Unit 3: Software Development Tools
3.3 Version Control System
What is a Version Control System
A version control system is about managing changes to an object. This means you manage a project in a "repository". From this repository users can make copies of it, the so called "working copy". After doing some changes on that working copy these changes can then be "checked in" to the repository again.
All changes have metadata, so they are logged:
- Author (Who)
- Timestamp (When)
- Short description (What)
Finally, each change has a unique identification (e.g. hash values, numbers, ...).
A typical process without version control
Sometimes it is necessary when working on a text or code that you can reproduce all changes on each file and that you can go back to a special version. How to do that? It could look like the following:
 As you can see, this has the potential to go out of hands very quickly. It is very easy to forget which file is which and what has changed between them.
As you can see, this has the potential to go out of hands very quickly. It is very easy to forget which file is which and what has changed between them.
Why Version Control System
The first positive aspect is to track changes, e.g. "Why does it say complexFunctionCall()"? The second usage is to manage contents (files), e.g. "I thought I sent you everything in that zip.". Furthermore, you can try out Dead Ends, e.g. "I rewrote everything, but that made everything worse, I have to go back to a clean state". While coding or writing you forget sometimes how things are working. Thus it is necessary to recover things, like, "I tried switching to jQuery before?". When you work on the same document or project in a team it's very helpful to simplify collaboration, e.g. "you write the GUI, I write the backend and we merge that". And finally espacially in coding separate development and stable development branches.
To put that all together you have the following advantages with a version control system:
- Logging via metadata
- Author (Who)
- Timestamp (When)
- Short description (What)
- Restoration of old intermediate states (and thus also archiving)
- Parallel work of several developers (coordination)
- Code base analyses
- Branching (Simultaneous development of several development branches)
📖 For further information read chapter 1 of the following literature:
Tsitoara, M. (2020). Beginning Git and GitHub: A Comprehensive Guide to Version Control, Project Management, and Teamwork for the New Developer (1st ed. 2020). https://doi.org/10.1007/978-1-4842-5313-7
You can get this e-book via opac service of our university.
Git
Git is an open-source tool and designed as distributed version control system. The program allows multiple developers to work on a project simultaneously, regardless of their location. Where other version control systems rely on a centrally stored database, Git relies on a distributed system. This means that each member of a project team has a sort of separate copy of the project database, the repository. Developers code mostly on their local copy of the repository and have the opportunity to share their changes with everyone involved. Distributing the repository also reduces the risk of losing data: Because many people have both the complete history and the current state of the project as a local copy at the same time, there is virtually no damage from a server failure.
Git also offers the ability to split a project into different branches or forks, for example, to separate versions and develop new or experimental features in parallel with the main branch. Changes to be published to the end user can then be merged back into the corresponding project version.
Usage of Git and GitHub
Git in itself is just a system to control the versioning of software. You can use it as a Terminal application (not easy for standard "mouse user"). On the other hand there are a variety of tools on the market that use Git as a base, adding a number of convenience features to make managing projects more convenient and accessible. Two examples are the web-based platform GitHub or SourceTree.
📖 For additional information about Git you have to read chapter 1.3*.
Commit
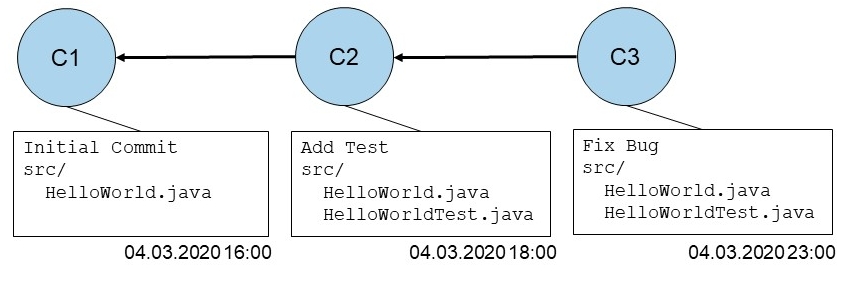
A commit is a snapshot of the whole project at a specific time. For example state of the development of my diabetes app today.
A commit stores
- All data in a compressed way: delta to predecessor
- His predecessor (e.g. C1 is predecessor to C2)
- "Commit Message", author, time...
Finally a commit is identified by his hash (in the following figure C1, C2 and C3).
Golden committing rules
- commit should be atomar (logical unit)
- project should compile without errors
- Unit Tests should work
- commitment text should include a short summary of your changes
- commit often!
Repository
A repository contains all files including previous versions. It is something like a file cabinet. This means that all changes made to a file in a repository are always available and it is possible to trace who, when, and what changes were made. What's special about Git is that each local working copy of a user is again a complete, separate, local repository. So there are multiple copies of the repository, the one who owns a clone, a so called working copy can work on it - including complete history, even offline and without dependence on a central server. The changes from your own repository/working copy can then be "pushed" back into the remote repository.
Important: do not touch your .git file.
Staging Area
The staging area is similar to a loading dock where you decide which changes are "shipped". The essential decoupling of the working directory and what Git stores allows developers to build their commits the way they want, not the way the VCS expects them to. You gain much more flexibility and control by having Git use a layer between the actual data stored.
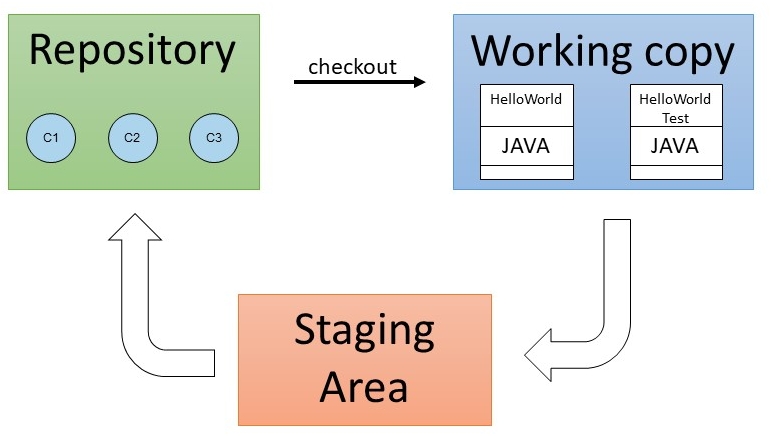
Three different states
- Modified means that a file has been modified but not yet checked into the local database.
- Staged means that a modified file is flagged in its current state for the next commit.
- Committed means that the data is securely stored in the local database.
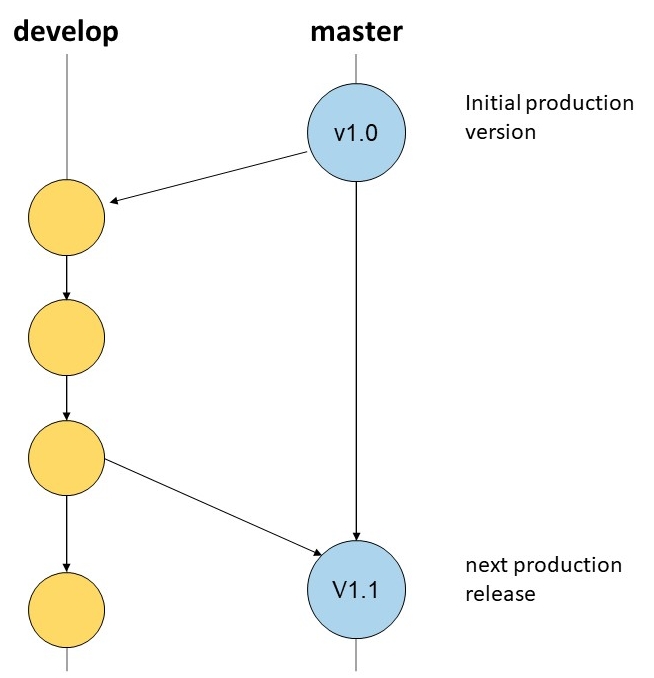
Branches
When using Git, branches are used to create a separate working branch. This can then be seen as a new context in which to work. For example, the programming of a security patch can be done in a separate branch (in the context of the patch), which is then incorporated back into the master branch when it is completed and after testing.
So a branch is needed to develop something detached on the basis of the current code, e.g. Bugfix, Feature, ... With a branch unstable code is kept from the stable remote.
📖 For additional information about Branches you have to read chapter 3.1*.
Merge
With merge, changes from another branch are transferred to the active branch. The changes that have been made in the meantime in the branch to be merged are applied to the current status in the active branch.
If there were no changes in the meantime, then there is no problem. But in general others are working on the same code and then you have to deal with conflicts.
📖 For additional information about Branches you have to read chapter 3.2*.
In-Depth Explanation
💡 Graphical Introduction into Gi(geman)* or GitHug the Game*.
Please note, that all additional literature (except to in-depth literature) mentioned in this chapter is also exam relevant!
* You will be forwarded to an external page. We are not responsible for the content of this site. There may be other regulations regarding data protection.